artykuł aktualizowany w sierpniu 2024
Post tłumaczy na czym tak naprawdę polega praca:
- analityka danych (DA)
- data scientista (DS)
- machine learning engineera (MLE)
Jako że ludzki umysł lubi porównania, przejdziemy sobie przez te wszystkie stanowiska porównując je między sobą – porównamy analityka pracującego na excelu do DA, DA do DS, a DS do MLE.
Zanim jednak przejdziemy do treści, chciałabym wytłumaczyć kilka założeń:
- porównania są na bazie moich doświadczeń i osób z którymi mam kontakt
- wpis jest dla osób początkujących – pewne generalizacje i uproszczenia są celowe, aby wytłumaczyć osobom, które nie są jeszcze w branży kwintesencję tych ról i różnice między nimi. Moim celem nie jest wymienienie każdej możliwej technologii, umiejętności czy zadania, które jest wymagane do każdej roli, bo wtedy musiałabym wypisać WSZYSTKO dla WSZYSTKICH.
- są ogromne różnice między stanowiskami w różnych firmach
- nie jest moim celem wartościowanie, która rola jest gorsza, a która lepsza. Każda ma swoje plusy i minusy i będzie odpowiednia dla innych osób w zależności od ich osobistych preferencji
Analityk vs Analityk Danych (DA)
Analityk X (np. finansowy, ds. logistyki, ds. marketingu, itd.) to osoba, która zajmuje się zarówno biznesem, jak i danymi. Jest to pracownik, który nie dość, że specjalizuje się w swojej dziedzinie biznesowej, to do tego posiada zdolności analityczne, które pomagają mu wypełniać swoje obowiązki. Analityk posiłkuje się danymi oraz liczbami aby podjąć właściwe decyzje biznesowe, które mają bezpośredni wpływ na firmę lub klientów. Z racji tego, że lwią częścią jego pracy są spotkania biznesowe, podejmowanie decyzji czy usprawnianie procesów, to jest to osoba, która nie jest w stanie poświęcić aż tyle czasu na dane, ile poświęca typowy analityk danych. Z powodu tego ograniczenia przeważnie używa prostych, powszechnych i łatwych do obsługi narzędzi, głównie excela, ewentualnie sięga po bardziej skomplikowane rozwiązania (np. dashboardy), ale zazwyczaj przygotowane przez inne osoby.
Analityk danych to osoba specjalizująca się w danych. Nie musi być specjalistą biznesowym w określonej dziedzinie, ponieważ nie zajmuje się stricte biznesem. Analityczka danych spędza cały dzień pracy nad danymi – ich przetwarzaniem, sprzątaniem, definiowaniem KPI, przygotowywaniem wizualizacji w formie dashboardów czy raportów. Taka osoba zazwyczaj nie podejmuje decyzji biznesowych sama, ale za to rekomenduje rozwiązania, które wynikają z interpretacji danych osobom decyzyjnym.
Z racji tego, że analitycy danych są profesjonalistami od danych, to charakteryzują się większymi kompetencjami w ich analizie oraz używają bardziej wyspecjalizowanych narzędzi niż excel. Używają baz danych, SQLa czy pythona, programów do wizualizacji jak Tableau lub Power BI. Jeżeli interesuje cię kariera DA to jak nim zostać dowiesz się w tym poście.
| Analityk Excelowy | Analityk Danych |
| specjalizuje się w swojej branży | jest specjalistą od danych |
| zajmuje się zarówno biznesem jak i analizą | zajmuje się tylko analizą |
| podejmuje decyzje biznesowe na podstawie danych | zazwyczaj nie podejmuje decyzji mających bezpośredni wpływ na biznes, ale rekomenduje podjęcie decyzji na podstawie danych innym osobom |
| z racji ograniczonego czasu używa prostych i łatwych narzędzi, np. excela | używa profesjonalnych narzędzi do obsługi rekordów, np. baz danych, SQL, narzędzi do wizualizacji |
Analityk Danych (DA) vs Data Scientist (DS)
Aby odpowiedzieć na pytanie czym różni się praca DA od pracy DS musimy sobie najpierw odpowiedzieć na pytanie w którym momencie zaczyna się data science, a kończy analiza danych.
Typowa analiza danych zazwyczaj polega na ogarnianiu danych “ręcznie”, np. znajdowaniu wzorców lub zależności między cechami przy użyciu wykresów lub statystyki opisowej (średnich, median, odchyleń standardowych). Wizualizacje oraz metryki statystyczne przeważnie są najlepszą metodą w przypadku, gdy porównujemy ze sobą 2-3 zmienne jednocześnie. Co jednak w przypadku, gdy tych zmiennych jest 20, 50 lub 200, a do tego wzajemnie ze sobą oddziałują w nieliniowy sposób?
Weźmy pod uwagę dane na poniższym wykresie. Jedno spojrzenie na wykres jest wystarczające, aby stwierdzić, że istnieje liniowa korelacja między zmienną X a zmienną Y (im większa wartość X, tym większa wartość Y), a do tego są oczywiste różnice między grupami. Prosta wizualizacja jest wystarczająca, by wytłumaczyć zależności istniejące między 3 cechami. Prawdopodobnie mając przed oczami wartości statystyczne, np. średnią czy percentyle każdej grupy, doszlibyśmy do tych samych wniosków (aczkolwiek wizualizacje są znacznie łatwiejsze do interpretacji przez nasz mózg).
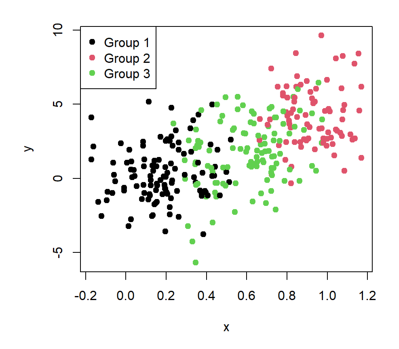
Powiedzmy jednak, że chcielibyśmy dołożyć do tego jeszcze jedną cechę. Już w tym momencie mamy problem, bo nie jesteśmy w stanie jej zwizualizować za pomocą wykresu 2D. A co, jeśli tych zmiennych jest jeszcze więcej? A gdy w dodatku zachodzą między nimi nieliniowe zależności, np. cecha Y czasami rośnie wraz z cechą X, a czasami maleje, a w dodatku zależy od różnych grup?
Nie chodzi tylko o to, że nie jesteśmy w stanie upchać tych wszystkich cech na jednym wykresie, no bo przecież możemy zrobić 50 różnych wykresów porównując po kolei każdą cechę z każdą. Chodzi także o to, że nasz mózg przestaje ogarniać – nawet mając pojedyncze wykresy nie będziemy w stanie zebrać tych wszystkich informacji w jedną całość.
Prawdziwy świat opiera się na nieliniowych, skomplikowanych zjawiskach opierających się na wielu zmiennych jednocześnie. Czy to znaczy, że nie jesteśmy w stanie za pomocą analizy zinterpretować tych informacji? Nie. Wtedy zaczynamy używać technik data science.
Data Scientist to osoba, która analizuje dane za pomocą wyspecjalizowanych algorytmów, uczenia maszynowego i sztucznej inteligencji. Istnieją różne algorytmy, które są w stanie rozwikłać skomplikowane zależności między danymi i wyciągnąć z nich najważniejsze informacje – zaczynając od prostej regresji liniowej, przechodząc przez drzewa decyzyjne, poprzez sieci neuronowe, po skomplikowane modele LLM. DS specjalizuje się w wyborze odpowiedniego narzędzia, dopasowaniu najlepszego algorytmu oraz doprecyzowaniu go tak, aby uzyskać jak najlepszy wynik.
Część obowiązków DS, które wychodzą poza wiedzę DA:
- znajomość po jakie narzędzie siągnąć w jakiej sytuacji – czy problem jest z kategorii klasycznego uczenia maszynowego, jest to problem NLP, czy może najlepszym rozwiązaniem będzie połączenie z modelem GPT od openAI
- wiedza jak przygotować dane pod algorytm – np. część modeli akceptuje tylko dane numeryczne bądź powinny być one znormalizowane
- znajomość ogólnych pojęć związanych z uczeniem maszynowym – np. jak podzielić dane na zbiór treningowy czy testowy i nie doprowadzić do przecieku danych między nimi, jak sprawdzić i co zrobić gdy model się przetrenowuje, jak mierzyć poprawność modelu
- znajomość algorytmów – jaki algorytm użyć w jakiej sytuacji, który z nich radzi sobie z nieliniowością, jakie dopasować do niego parametry
Stack technologiczny DS:
- python – główne narzędzie DS. Służy między innymi do zbierania danych (biblioteki requests, BeautifulSoup), eskploracyjnej analizy danych i ich przerabiania (pandas, numpy, matplotlib, seaborn), statystyki i budowania modeli ML (SciPy, statsmodels, sklearn, xgboost, pytorch itd), automatyzacji i masy innych rzeczy
- SQL – zanim zaczniemy pracować w pythonie musimy pobrać skądś dane. Większość firm przechowuje dane w relacyjnych bazach danych, zatem musimy znać SQL, żeby je wyciągnąć
- infrastruktura – wynikiem pracy DA jest często pewna forma wizualizacji – raport, prezentacja, dashboard. Zazwyczaj tworzy się je w określonym środowisku, ewentualnie pracuje na 2 środowiskach zintegrowanych ze sobą (np. musimy wrzucić dane z bazy danych do jupytera, lub zintegrować bazę z programem do wizualizacji). Jednak w przypadku DS tych środowisk zazwyczaj dochodzi więcej – przejdziemy zaraz do tego tematu w przypadku omawiania MLE.
Kilka dodatkowych aspektów, które różnią się między DA i DS i o których warto wspomnieć:
- Specjalizacji uczenia maszynowego i sztucznej inteligencji jest MASA. Można robić regresje, klasyfikacje, prognozowanie, systemy rekomendacji, przetwarzanie tekstu, przetwarzanie obrazu, detekcje anomalii, klastrowanie i jeszcze więcej innych rzeczy. Nie jesteśmy w stanie być ekspertami w każdej z tej dziedziny, ba, niełatwo nawet nadążyć za wszystkimi nowościami z jednej! Algorytmów, podejść i rozwiązań jest tak dużo, że ciężko znać się na wszystkim. Przez to nieodłączną częścią pracy DS jest ciągły research i działanie z nieznanym.
- Projekty są zazwyczaj długie i mega iteracyjne. W wielu przypadkach zbudowanie modelu to nie kwestia tygodni, lecz raczej miesięcy lub czasem lat. W dodatku jest to proces intensywnie iteracyjny: budujemy model, sprawdzamy wynik, zmieniamy coś w modelu, sprawdzamy jego wynik, zmieniamy coś innego, sprawdzamy wynik, itd… i tak przez kilka miesięcy…
| DA | DS |
| analizuje prostsze, zazwyczaj liniowe zależności bez użycia algorytmów, ML i sztucznej inteligencji | analizuje skomplikowane, nieliniowe zależności przy użyciu algorytmów, ML i sztucznej inteligencji |
| wyniki zazwyczaj w formie wizualizacji | wyniki zazwyczaj w formie predykcji modelu |
| różne projekty, ale zdarzają się krótsze i dłuższe | zazwyczaj długie, iteracyjne projekty |
| używa głównie SQL, programów do wizualizacji, jeżeli pythona to bibliotek związanych z danymi | używa pythona (związanego z danymi i “ogólnego”), SQL, musi znać się na infrastrukturze |
Data Scientist (DS) vs Machine Learning Engineer (MLE)
Rola MLE w firmie zależy w dużej mierze od zakresu obowiązków DS. Celem obydwu stanowisk jest tworzenie modeli uczenia maszynowego, ale różnią się one zakresem, w jakim się specjalizują – DS specjalizuje się w znajomości algorytmów, modeli i statystyce, a MLE specjalizuje się w produkcji i automatyzacji modeli.
Co to znaczy produkcja i automatyzacja modelu? Pewnie robiąc kursy z machine learningu w większości przypadków wrzucacie dane z pliku CSV do środowiska jupytera notebooka i tam piszecie cały kod. Jednak aby model był w stanie komuś posłużyć, często trzeba go zautomatyzować – i jak się okazuje to całkiem skomplikowane przedsięwzięcie.
Wyobraźmy sobie takie flow:
- ściągamy dane z bazy danych (DB) i wrzucamy je do pythona – potrzebujemy zintegrować DB z pythonem
- robimy obróbkę danych w pythonie, taką samą dla 3 różnych modeli. Powiedzmy, że przetworzenie danych jest dość ciężkie obliczeniowo, więc aby nie powtarzać niepotrzebnie tego procesu trzy razy to robimy to raz, a następnie zapisujemy przetworzone dane w chmurze – musimy zatem zintegrować python z chmurą
- trenujemy modele ML na próbce danych: pobieramy próbkę przetworzonych rekordów z chmury, trenujemy modele w pythonie, zapisujemy modele w chmurze
- robimy predykcje ML na całych danych: pobieramy z chmury resztę danych i wytrenowane modele, robimy predykcje
- wysyłamy predykcje do DB oraz eksponujemy dla frontendu przez API – znowu pojawia się integracja z DB, w dodatku dochodzi do tego wysyłanie danych przez API.
O czym jeszcze nie wspomnieliśmy? O tym, że ten kod pythonowy musi się przecież gdzieś “odpalać” – zazwyczaj znowu dzieje się to w chmurze, w jakimś specjalnym środowisku. Tutaj pojawia się kolejny problem – co to jest za środowisko? Co, jeżeli wersja pythona i zainstalowanych na nim bibliotek nie zgadza się z wersjami, na których pisaliśmy nasz kod? Dlatego często używa się konteneryzacji (np. dockera), która jest czymś w stylu wirtualnej maszyny, w której to my wszystko definiujemy – w tym jaka wersja pythona i bibliotek jest tam zainstalowana.
Ok, czyli mamy już kod pythonowy, umieszczony w dockerze w chmurze, ale jak i kiedy go będziemy odpalać? Dochodzi do tego kolejne narzędzie tzw. schedulery (np. airflow), które służą do harmonogramowania zadań.
Dobra, to co próbuję tutaj przekazać to to, że produkcja kodu to całkiem skomplikowane przedsięwzięcie. Różni się to trochę od jednej linijki kodu w jupyterze importującej plik CSV i kliknięciu “Run all cells”.
Machine Learning Engineer to osoba, która specjalizuje się w produkcji modeli – ogarnia infrastrukturę, pythona, a „przy okazji” tworzy modele ML. Bywają firmy, gdzie DS też to wszystko robi, ale tak jak już wspominałam, DS będzie raczej się specjalizował w samych modelach – nierzadko stworzy lepszy, bardziej dopracowany model i będzie znał się na matematyce stojącej za algorytmami, ale może mieć problem z integracją różnych systemów i napisaniem dobrego, programistycznego kodu – i tutaj pomoże mu MLE. MLE to często osoby z backgroundem programistycznym, które nie specjalizują się np. w frontendzie czy backendzie, ale właśnie w produkcji ML.
Zadania DS i MLE często się nakładają i zależą dość mocno od tego, co potrafi osoba na drugim stanowisku – czasami DS będzie skupiał się tylko na modelach i researchu, a część z automatyzacją kodu zostawi już MLE, a czasami oba te stanowiska robią mniej więcej to samo, ale wspierają się wzajemnie i uzupełniają. Zazwyczaj DS ma inny sposób pracy niż MLE – MLE zazwyczaj mają nastawienie bardziej programistyczne niż analityczne, dlatego ich praca bardziej przypomina pracę programisty, gdzie np. taski są rozbijane do drobnych zadań tak jak to ma miejsce w przypadku typowych programistów. MLE zazwyczaj są lepszymi programistami, programują bardziej obiektowo (python jest językiem obiektowym – chodzi o to, że bardziej tworzą klasy i funkcje niż piszą kod, który jest wykonywany linijka po linijce), znają się na dobrych praktykach programistycznych np. pisaniu unittestów.
| DS | MLE |
| specjalizuje się w samych modelach ML i statystyce | specjalizuje się w produkcji (automatyzacji) modeli ML |
| zna się na poprawnym podejściu do danych | zna się na programowaniu i infrastrukturze |
| często osoba z backgroundem matematycznym, statystycznym lub analitycznym | często osoba z backgroundem programistycznym |
| długie, iteracyjne projekty | długie projekty zazwyczaj rozbite do krótszych zadań |
| specjalizuje się w SQL i pythonie związanym z danymi | specjalizuje się w pythonie “ogólnym” i infrastrukturze (chmura, docker, bash, itd.) |
A co z data engineer (DE)?
Być może część się zastanawia, dlaczego brakuje w moim zestawieniu data engineera. Pominęłam go, ponieważ wpada on do trochę innej kategorii – po prostu jego rolą nie jest analiza lub interpretacja danych. Inżynier danych zajmuje się zbieraniem danych i ogarnianiem infrastruktury związanej z danymi, np. utrzymywaniem baz danych. Nie interesuje go za bardzo co się dzieje z tymi danymi dalej, czyli jakie informacje można go z nich wyciągnąć.
Nowa rola – Analytics Engineer
Wraz z rozwojem używania danych w firmach pojawiają się coraz większe specjalizacje, np. rola Analytics Engineer, która jest fuzją Analityka Danych z Data Engineerem. Jeżeli interesują cię szczegóły tej pozycji to zapraszam na osobny artykuł na blogu na jej temat.
Podsumowując
Przeszliśmy razem przez wszystkie stanowiska powiązane z analizą i interpretacją danych, od analityka excelowego, przez analityka danych, data scientista po machine learning engineera.
Należy pamiętać, że to jak wygląda rzeczywista praca zależy w dużej mierze od firmy i używanych w niej narzędzi, oraz że jest ogromny overlap między tymi rolami. Jeżeli chcemy zostać data scientistem, to znalezienie oferty z napisem “data scientist” nie wystarczy – musimy sami się upewnić na rekrutacji, że rolą pracownika będzie rzeczywiście robienie data science i modeli ML.
Dla mnie osobiście różnice między tymi rolami wynikają z faktu, że nie można mieć wszystkiego – jeżeli regularnie uczestniczymy w wielu spotkaniach biznesowych, to nie spędzimy tego czasu na programowaniu – mniej czasu na programowaniu znaczy, że nie jesteśmy w stanie wypróbować nowych bibliotek czy napisać funkcji w trochę lepszy sposób niż zazwyczaj – dlatego “cierpią” na tym nasze zdolności techniczne. Z drugiej strony, jeżeli siedzimy cały dzień w kodzie, to często nie wiemy co się dzieje w biznesie, dlatego mogą nas ominąć informacje, które są istotne dla naszej analizy. Dlatego ja widzę te wszystkie role jako role polegające na interpretacji danych, ale z pewnym odchyleniem albo w stronę świata biznesu, albo w stronę IT. Sęk w tym, aby odnaleźć na tej osi miejsce, które najbardziej będzie nam pasować.

Jeżeli nie chcecie przegapić nowych treści, zapraszam do zapisu do newslettera:
keywords: analityk danych, analityk biznesowy, data scientist, co to data science, czym zajmuję się data scientist, czym zajmuje sie data scientist, data scientist czym się zajmuje, data scientist co robi, data scientist zarobki, data scientist a data engineer, data scientist a data analyst, data scientist a analityk danych, data science kto to, data science jak zacząć, data science jak zaczac, data scientist jak zacząć, data scientist jak zaczac, jak zostac data science, jak zostac data scientist, kierunek data science, kto to data scientist, kto to jest data scientist, data scientist obowiązki, data scientist opis stanowiska, data scientist po polsku, data scientist blog, data science blog, data scientist czy warto, data scientist vs ml engineer, data scientist vs machine learning engineer, data scientist vs statistician, analytics engineer, sztuczna inteligencja, praca z sztuczną inteligencją
A jak różnią się zarobki na tych stanowiskach? O ile rosły u Ciebie po kolejnych zmianach pracy?
Byłam po kolei na stanowiskach: junior i mid analityk, junior i mid DA, mid DS i mid MLE i średnio na każdym tym stanowisku miałam przeskok o 25% netto przy UoP (chociaż wiązało się to też z faktem, że od mid DA mam w umowie podwyższone koszty uzyskania przychodu przy kosztach autorskich). Zaczynałam od całkiem ok korporacyjnej stawki, trochę standard jak na pozycję z silnym excelem bez doświadczenia. Sory, trochę zawile, ale póki co nie chcę się dzielić publicznie stawkami.
Z mojego doświadczenia wynika, że właśnie ten przeskok z analityka excelowego na DA z SQL to największy wzrost procentowy. W firmach widełki na DS są zazwyczaj przesunięte w stosunku do widełek na DA, ale np. o 20-30%, czyli junior DS będzie zarabiał więcej niż junior DA, ale pewnie nie pobije stawki od senior DA. Czyli moim zdaniem finansowo bardziej opłaca się być DA na wyższym seniority niż próbować przebranżowić się na DS, tym bardziej biorąc pod uwagę ile trzeba się nauczyć.
Jak się jest już naprawdę dobrym DS/MLE to można zarabiać bardzo dobre stawki, szczególnie pracując na B2B dla zagranicznej firmy, ale wiadomo, że nie każdy dojdzie do takiego poziomu. Ogólnie jednak uważam, że średnie zarobki są gorsze niż dla typowych programistów, szczególnie dlatego, że jest mniejsza ilość ofert (firma zazwyczaj bez ML sobie poradzi, ale bez aplikacji już nie).
Dzięki za odpowiedź! Po cichu liczyłem na konkretne kwoty, ale w pełni rozumiem, że nie chcesz podawać tego publicznie. A zapytałem, bo to temat, który wydaje mi się, że pasuje do Twojego stylu pisania, tzn zero bullshitu, a wokół pieniędzy też krąży dużo mitów i aura tabu. Mam wrażenie, że w czystym IT/programowaniu bardziej nie owija się w bawełnę, a w tematach analitycznych/DS ludzie przeceniają racjonalność rekrutujących, przeceniają umiejętności, które trzeba mieć żeby dobrze zarabiać i mało kombinują. 🙂 Nie twierdzę, że wiedza nie ma znaczenia, ale rekrutacje to też trochę gra i czasami szczęście.
Ja jestem specjalistą w konkretnej dziedzinie w branży finansowej, pracuję głównie z SQL-em, zarobki to na ten moment 12-13 k brutto UoP. Chcę się przestawić na DA, docelowo DS, bardziej żeby się mniej nudzić i zmienić branżę, no i kombinuję jak to zrobić, stąd też pytanie. Na ten moment próbuję to zrobić trochę na skróty, tzn przy kolejnej udanej rekrutacji już jako DA przejść na B2B za ekwiwalent UoP, czyli trochę więcej niż obecne brutto UoP na fakturze, a na rękę znacząco więcej. Myślę, że mając już podstawy Pythona jest to realne, ale zobaczymy. 🙂
Ciekawe co napisałaś o zagranicznych firmach – może temat na jakiś wpis gdzie szukać dobrych ofert?
Też chciałabym się tym podzielić, ale trochę mi głupio wypisywać konkretne zarobki bez żadnego wytłumaczenia dokładnie co robiłam i ile byłam na jakim stanowisku, a w dodatku nie wiem czy moi pracodawcy sobie tego życzą. Ale chciałabym się tym kiedyś podzielić.
Co do rekrutacji to jest dokładnie tak jak piszesz – stąd też moje wpisy rekrutacyjne, gdzie próbuję wytłumaczyć, że są etapy na których liczy się tylko pewność siebie. Aczkolwiek na rekrutacji DS/MLE coraz bardziej wygląda to jak w IT, do tego są etapy techniczne, gdzie np. przez godzinę jest się wałkowanym z pytań z DS i pythona, tam już nie ma miejsca na szczęście.
Myślę, że Twój plan jak najbardziej realny do zrealizowania, z doświadczeniem SQLowym i podstawami pythona możesz celować w mid/senior DA.
Temat zapisuję do listy, ale tak sobie teraz myślę, że jest chyba jeden temat a propos zarobków, który powinnam poruszyć w najbliższym czasie (słowo klucz: opcje w startupach).
kawał roboty, uwielbiam Twojego bloga!!
Aaaaaa dziękuję serdecznie!