artykuł aktualizowany we wrześniu 2024
Dane, dane, dane.
Czy wkrótce zdolność analizy danych przestanie być czymś ekstra, a zacznie być pospolitą umiejętnością standardowo wymaganą przy rekrutacji na różne stanowiska, tak jak to się stało z językiem angielskim? Powoli zmierzamy w tym kierunku – firmy coraz częściej podejmują decyzje na podstawie danych, przez co coraz więcej osób na przeróżnych pozycjach zaczyna je nie tylko interpretować, ale także analizować.
Próg wejścia do analizy danych praktycznie nie istnieje – no bo co to za problem chociażby zsumować kilka wierszy w excelu – co już de facto jest jakąś analizą. Jeżeli je zsumujemy to możemy też wyciągnąć średnią, narysować wykres liniowy i już analiza gotowa. Niestety uważam, że ten niski próg wejścia jest większym przekleństwem niż błogosławieństwem, ponieważ daje złudne poczucie kontroli. Jakaś analiza danych jest prosta, ale poprawna analiza danych jest cholernie trudna. Dlaczego? Bo nie istnieje gotowy przepis jak ją wykonać: jak posprzątać i przygotować dane, jak co policzyć i które miary wybrać. A zaufaj mi, wyciąganie wniosków na podstawie niepoprawnej analizy to ostatnie co chcesz zrobić. W tej sytuacji lepiej odpuścić i nie robić analizy wcale.
Jak zrobić analizę poprawnie? Nauczyć się jak się pracuje z danymi. I to właśnie ma na celu ten artykuł: wytłumaczyć kompletnemu laikowi jak analizować dane, od czego zacząć, na co zwracać uwagę i gdzie czyhają błędy.
A jeżeli interesują cię takie tematy to koniecznie zapisz się do newslettera, aby nie przegapić nowych treści i dostawać dodatkowe materiały (np. quiz jak analizować dane lub dodatek do tego artykułu):
1. Analiza bez celu nie istnieje
Często na konsultacjach zgłaszacie, że macie już te dane i nie wiecie… co z nimi zrobić. Co wy tam macie analizować. Jak to się robi tą analizę danych. Wtedy ja zadaję te magiczne zapytanie: ale jaki jest twój cel? Co planujesz uzyskać?
Nie ma czegoś takiego jak ogólna analiza danych. Analiza zawsze jest ukierunkowana pod konkretny cel, nie da się w jakiś ogólny sposób podchodzić do danych. Każdy etap od samego początku, włączając w to czyszczenie, przetwarzanie, wybór metryk czy tworzenie wizualizacji, będzie inaczej przebiegał w zależności od tego, co chcesz uzyskać, nawet praca na tym samym zbiorze danych będzie odmienna w zależności od zamiaru. Zanim cokolwiek zrobisz z danymi postaw sobie cel i miej cały czas go z tyłu głowy podczas twojego działania.
2. Analiza danych opiera się na liczbach
Dane to zbiór informacji. Przykładem danych mogą być informacje o klientach w sklepie internetowym: ich płeć, wiek, adres zamieszkania, szczegóły o dokonanych przez nich transakcjach: kwotach, kupionych produktach, datach zakupów, itd.
Wśród danych wyróżniamy różne typy danych. Najpopularniejsze to dane numeryczne, czyli liczby (wiek, kwota zakupu) oraz kategorialne, czyli kategorie (płeć, produkty), ale wyróżniamy także dane geograficzne (adres zamieszkania), czas (data urodzenia) i inne typy.
Mimo iż dane to nie tylko liczby, to analiza opiera się na liczbach. Celem analizy jest wyciągnięcie wiedzy ze zbioru danych, czyli w powyższym przykładzie dowiedzeniu się kim są klienci tego sklepu i jakich dokonują zakupów. Co możemy sprawdzić aby uzyskać taką wiedzę:
- policzyć kobiety i mężczyzn
- obliczyć średni wiek kobiet i mężczyzn
- obliczyć ile dni średnio minęło od ostatniego zakupu
- policzyć ile km klienci średnio zamieszkują od miasta wojewódzkiego
- obliczyć ile % klientów dokonało więcej niż jednego zakupu
Jak widzisz na powyższych przykładach wszystko sprowadziliśmy do liczb: albo przypisaliśmy liczby do danych (zliczenie przypadków czy policzenie średniej na kategorię), albo wręcz zamieniliśmy dane nieliczbowe na liczby (data zakupu -> ilość dni; adres zamieszkania -> km od miasta).
Dlaczego zrównujemy wszystko do liczb? Jaką przewagę dają nam liczby?
3. Porównywanie jest podstawą analizy
Czy sprzedanie 300 produktów w lokalnym sklepie to dobry wynik? Czy miesięczny przychód 20 000 zł jest zadowalający? Czy marża 5% jest wystarczająca? W sumie… ciężko powiedzieć. Każda z tych liczb jest tylko liczbą i wyrwana z kontekstu rzadko dostarcza nam jakąkolwiek wiedzę. Dlatego często porównujemy liczby między sobą. Możemy porównywać kategorie, np. jak 300 produktów w jednym sklepie wypada na tle innych sklepów: jeżeli podobny sklep sprzedaje 200-400 produktów, to jesteśmy na tym samym poziomie, a jeżeli nie schodzą poniżej 600 produktów to nasz sklep wypada gorzej.
Często porównujemy także jak liczby zmieniają się w czasie. Miesięczny przychód na poziomie 20 tys. jest świetnym wynikiem jeżeli nigdy wcześniej nie przekroczyliśmy 15 tys., ale beznadziejnym, jeżeli wszystkie poprzednie miesiące osiągały sprzedaż powyżej 30 tys.
Jednak przy porównywaniu pojawiają się pierwsze pułapki analizy:
- Warto zwracać szczególną uwagę czy porównanie ma sens. Jeżeli sklep ma sprzedaż sezonową i w grudniu zawsze osiągamy najlepsze wyniki to bez sensu porównywać grudzień do listopada, lepiej porównać go z grudniem zeszłego roku. A zresztą każdy miesiąc ma inną liczbę dni co też będzie rzutowało na wyniki – w tym przypadku można podzielić sumę przychodu przez liczbę dni w miesiącu.
- Często w porównaniach wykorzystujemy procenty. Procenty mają rację bytu tylko w przypadku dużych i stabilnych wartości, w innych przypadkach wręcz mogą wprowadzić zamęt czy zamaskować fakty.
4. Co to jest agregacja i dlaczego jest tak ważna?
Zostając w temacie porównań – czy jest sens porównywać, np. wynik sprzedaży całego działu z wynikiem sprzedaży pojedynczej usługi? Wydaje się to bez sensu. Jakie dane zatem zestawiać ze sobą? Zagregowane do tego samego poziomu. Agregacja to poziom do którego sprowadzamy obliczenia.
Za każdym razem, gdy analityk danych dostanie polecenie do obliczenia jakiejś wartości (np. przychodu) to jedno z jego pierwszych pytań brzmi “na jakim poziomie to obliczyć?”. Cokolwiek liczymy możemy to liczyć na różnych poziomach: przychód może być zsumowany dla całej firmy, jednego działu, usługi, czy może być to średni przychód na klienta.
Agregacja to cholernie ważny koncept w analizie danych. Jest to chleb powszechni dla osób pracujących na danych, a zarazem koncepcja często pomijana przez osoby nietechniczne. Nieraz widziałam sytuacje w których “laicy” próbują połączyć w obliczeniach liczby zagregowane na różnych poziomach. Dlatego cokolwiek liczymy warto mieć zawsze z tyłu głowy na jakim poziomie chcemy to policzyć.
Szczególnym rodzajem agregacji jest czas, który jest bardzo często wykorzystywany właśnie z potrzeby porównywania zmian w czasie. Rzadko kiedy liczymy coś dla całego zbioru danych – zazwyczaj zliczamy dane np. z ostatniego tygodnia, miesiąca czy kwartału. Dlatego dane regularnie są agregowane zarówno na poziomie biznesowym i czasowym, np. suma przychodu na dział podróżniczy dla zeszłego miesiąca.
5. Co mierzyć? Miary i rozkłady
Kolejnym pytaniem na które musimy odpowiedzieć podczas analizy jest co chcemy obliczyć. Jeżeli chcemy wiedzieć ile wydaje typowy klient w sklepie podczas jednej transakcji to możemy obliczyć średnią kwotę wydaną przez klienta na transakcję w ciągu ostatnich 30 dni.
Średnia jest tzw. miarą tendencji centralnej, czyli wskazuje “środek” przedziału. Na pierwszy rzut oka wydaje się dobrym wyborem, ale niestety średnia wyznacza środek tylko w przypadku wartości mających rozkład normalny.
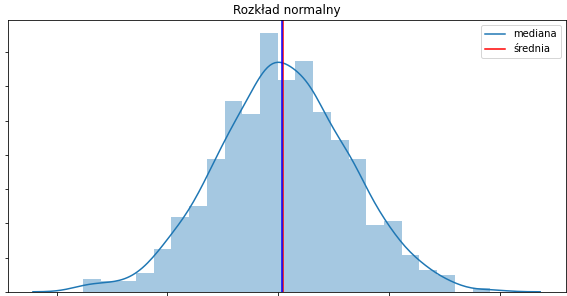
Obstawiam w ciemno, że wydane kwoty podczas jednej transakcji nie będą miały rozkładu normalnego, tylko prawoskośny. Z mojego doświadczenia wynika, że rozkład normalny jest rzadko spotykany w biznesie. W takim przypadku średnia nie jest najlepszym wyborem, ponieważ dałaby złudne wrażenie, że klient wydał więcej niż autentycznie wydał. Analiza prowadziłaby do błędnych wniosków, czego absolutnie chcemy uniknąć.
Zamiast średniej lepszym rozwiązaniem byłoby użycie mediany, która wyznacza dokładny środek rozkładu: 50% przypadków ma wartość poniżej mediany, a 50% powyżej.
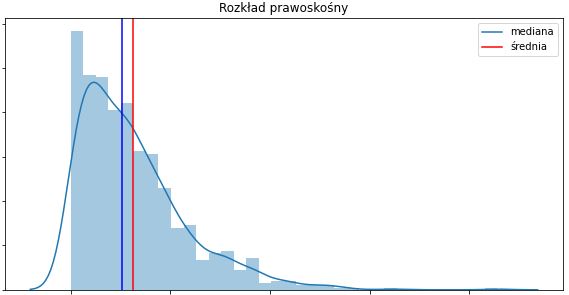
Ale czy użycie mediany rozwiązuje każdy problem? Spróbujmy użyć przykładu, aby się tego dowiedzieć. Załóżmy, że na mamy w pomieszczeniu 10 osób o określonym wieku:
- W pierwszym pomieszczeniu znajduje się 10 studentów drugiego roku. Ich wiek to: 19, 20, 20, 21, 22, 19, 20, 20, 20, 25. Ich średnia wynosi 20.6, a mediana 20.
- W drugim pomieszczeniu znajdują się uczniowie pierwszej klasy wraz z rodzicami. Wiek poszczególnych osób to: 7, 7, 7, 6, 7, 34, 33, 32, 35, 40. Średnia wieku wynosi 19.5, a mediana 20.8.
Mimo że pomieszczenia są wypełnione całkowicie różnymi ludźmi, to zarówno średnia jak i mediana są do siebie podobne w obydwu pomieszczeniach i nie dostarczają informacji kto rzeczywiście się w nich znajduje!
Problemem jest tutaj nie niewłaściwy wybór miary, ale próba zrozumienia całej grupy za pomocą jednej liczby, co… nigdy się nie uda! Pojedyncza liczba nigdy nie będzie w stanie wytłumaczyć rozkładu wszystkich obserwacji, co tak naprawdę jest kluczem do zrozumienia danych. Jak zatem dowiedzieć się jak wygląda cały rozkład? Albo spojrzeć na dodatkowe metryki takie jak odchylenie standardowe (mowiące jak daleko poszczególne przypadki wypadają od średniej) lub dodatkowe spojrzenie na 25 czy 75 percentyl (wartości poniżej których znajduje się 25% / 75% przypadków). Ale najlepszym sposobem byłoby po prostu spojrzenie na wszystkie dane. Jak to zrobić? Tworząc wykres!
6. Wizualizuj, wizualizuj i wizualizuj
Ludzki mózg wyewoluwał, aby polegać w głównej mierze na zmyśle wzroku, zatem nic dziwnego, że wzrok odgrywa znaczącą rolę także w procesie analizie danych. Analiza żyje w symbiozie z wizualizacjami do tego stopnia, że nie użycie wykresu podczas analizy jest wręcz wyjątkiem od reguły. Dlatego analizując dane wizualizuj, wizualizuj, oraz wizualizuj.
Jak tworzyć dobre wizualizacje:
- Wykresy powinny być proste. Dobry wykres to wykres przy którym nie musimy się wysilać, aby go zrozumieć. Jeżeli odbiorca nie rozumie wykresu to wina autora wizualizacji, a nie odbiorcy. Każdy wykres powinien mieć opis, tytuł, legendę, jednostki, i nie powinien zawierać zbyt dużo informacji.
- Ludzki umysł dużo lepiej porównuje odległości niż powierzchnie, dlatego najlepsze wykresy to te oparte na odległościach, np. wykresy słupkowe czy liniowe. Powinniśmy omijać wykresów kołowych lub (co gorsza) 3D.
7. Dane wymagają sprzątania
Nie bez powodu wszędzie powtarzają, że osoby pracujące na danych spędzają więcej czasu na ich czyszczeniu niż na samej analizie. Nawet ciężko powiedzieć, że dane zazwyczaj wymagają posprzątania, bo dane praktycznie zawsze wymagają posprzątania.
Co to znaczy posprzątać dane? Poradzić sobie z:
- złymi danymi (np. wiek
9999, płećkobitazamiastkobietaitd.) - brakującymi wartościami – może to być zarówno niekompletny zbiór (np. brak całego działu) jak i brak pojedynczych informacji w wybranych kolumnach
- skrajnymi wartościami zaburzającymi naszą statystykę, tzw. outlierami
- duplikatami, czyli powtarzającymi się rekordami (np. gdy ten sam użytkownik ma dwa różne konta)
Powyższe problemy trzeba zaadresować. Jeżeli nie masz zamiaru tego robić, to nie rób analizy. Nieprawdziwe dane mogą zaburzyć analizę i nie mówimy tutaj o jakiś drobnym czy pomijalnym problemie, ale o poważnym zagrożeniu mającym znaczący wpływ na końcowy wynik. Dlatego nie istnieje profesjonalna analiza danych bez ich posprzątania. Złe lub brakujące wartości i duplikaty trzeba poprawić lub usunąć, a wartości skrajne należy zamienić lub wybrać metryki odporne na takie przypadki (np. mediana zamiast średniej, boxplot zamiast wykresu słupkowego).
Jak sprawdzić prawidłowość danych:
- Spójrz na surowe dane (pojedyncze i nieprzetworzone wiersze) i zobacz czy wartości tam występujące mają sens. Często na pierwszy rzut oka już można zauważyć coś podejrzanego, np. to, że masz same kobiety w danych albo że jakaś kolumna jest zbyt często pusta.
- Sprawdź czy wartości minimalne i maksymalne mają sens, np. kwota zakupu nie powinna być ujemna a wiek powyżej 110 lat.
- Sprawdź czy są duplikaty – np. jeżeli dane są zagregowane na poziomie klienta to liczba wierszy powinna się równać liczbie unikalnych użytkowników.
- Sprawdź podstawowe obliczenia na prostych agregacjach i zobacz czy mają sens – np. policz kobiety i mężczyzn, sprawdź liczbę transakcji.
- Skonfrontuj wyniki ze swoją wiedzą. Zdarza się, że dopiero po skończeniu analizy zauważamy coś dziwnego. Gdy ma to miejsce sprawdź skąd to może wynikać.
8. Nasz mózg szuka przyczynowości
Jedną z rzeczy, którą najbardziej zapamiętałam z uczęszczania na studia neurobiologiczne jest to, że nasz mózg ciągle próbuje wytłumaczyć otaczającą nas rzeczywistość szukając związku przyczynowo-skutkowego.
Widzimy jakiś trend w danych? Nasz mózg już pędzi z wytłumaczeniem! Spadek sprzedaży? Hmm, zmieniliśmy ostatnio design strony, klienci pewnie są zagubieni i nie mogą znaleźć produktów. Wzrost sprzedaży? Przecież zmieniliśmy ostatnio design strony, musi być dużo czytelniejszy niż wcześniejszy! I o ile w niektórych przypadkach rzeczywiście ma to sens, to jednak radzę powstrzymać się od wyciągnia zbyt pochopnych wniosków.
Pewnie już słyszeliście, że korelacja to nie przyczynowość i znacie ten słynny przypadek w którym ilość spożytkowanej czekolady jest skorelowana z ilością nagród nobla. Ale chciałabym uczulić, że problem nadinterpretowania pojawia się już wcześniej – widzimy trendy, które nie istnieją, lub interpretujemy różnice między grupami, które nie są rzeczywistymi różnicami.
Zresztą stwierdzenie czy rzeczywiście istnieje różnica między grupami wcale nie jest takie proste.
Jeżeli mediana transakcji dla kobiety wynosi 100 zł, a dla mężczyzn 101 zł, to czy możemy powiedzieć, że istnieje różnica między płciami? A co, jeżeli jest to 100 vs 109 zł? Albo 100 vs 130 zł? No dobra, 100 vs 130 tu już jest różnica 30%, więc jest to istotna różnica. Chociaż… no właśnie… tak to nie działa.
Aby określić czy różnica między grupami jest przypadkiem czy autentycznym zjawiskiem używamy testów statystycznych. Testy te nie patrzą tylko na wielkość różnicy, ale także na rozkłady wartości w obydwu grupach. Im wartości są bardziej homogeniczne, czyli kobiety podobne do innych kobiet, a mężczyźni do innych mężczyzn, tym mniejsza musi być różnica między grupami aby wykazać tzw. istotność statystyczną.
Grupy homogeniczne:
- Kobiety mają transakcje o kwotach: 99, 100, 97, 102, 105. Średnio 100.6
- Mężczyźni mają transakcje: 100, 110, 107, 109, 113, 108. Średnio 107.8
Grupy heterogeniczne:
- kobiety: 70, 150, 50, 10, 100. Średnio 76.
- mężczyźni: 110, 200, 180, 70, 300. Średnio 172.
I chociaż w pierwszym przykładzie średnia różnica między płciami jest dużo mniejsza (100.6 vs 107.8) niż w drugim (76 vs 172), to właśnie według testu statystycznego (tzw. Wilcoxa) to właśnie pierwszy przykład zawiera różnice istotnie statystycznie, a nie drugi. W drugim przypadku jest zbyt duża rozbieżność między obserwacjami aby udowodnić, że różnice w transakcjach wynikają z płci.
Testy statystyczne często są używane w tzw. testach A/B gdzie oprócz istotności statystycznej możemy także zbadać przyczynowość. Same przeprowadzenie testów sprawdza istnienie różnic między grupami, ale nie dowodzi czy różnice wynikają z korelacji czy związku przyczynowo-skutkowego. Korelacja ma miejsce gdy zjawiska X i Y występują w podobnym czasie, podczas gdy związek przyczynowo-skutkowy ma miejsce gdy X prowadzi do Y.
Ale nie wystarczy wprowadzić aspektu czasowego i zbadać różnice przed i po. Wprowadzając nowy design strony nie wystarczy zmierzyć liczby transkacji przed i po jego wprowadzeniu. Musimy jeszcze udowodnić, że zmiana nie wynika z samego aspektu czasowego. Gdybyśmy wprowadzili nowy design na przełomie listopada i grudnia, a wiadomo, że w grudniu liczba transkacji jest zazwyczaj wyższa to moglibyśmy dojść do błędnego wniosku, że różnica jest spowodowana nowym designem. Musimy dowieść, że różnice w ilości transakcji wynikają tylko i wyłącznie z wprowadzenia nowego designu strony.
Kluczem testów A/B jest eksperyment, w którym dzielimy klientów na 2 (lub więcej) grupy:
- grupa kontrolna: klienci widzą stary design strony
- grupa eksperymentalna: klienci widzą nowy design strony
W tym samym czasie klienci z grupy kontrolnej widzą starą stronę, a klienci z grupy eksperymentalnej nową stronę – eliminujemy zatem wpływ czasu i innych aspektów na wyniki. Jedyna różnica między tymi klientami to design strony. Następnie porównujemy ilość transakcji w grupach wykonując testy statystyczne, a jeżeli otrzymamy istotność statystyczną to możemy stwierdzić, że rzeczywiście nowy design strony ma wpływ na liczbę transkacji.
9. Poprawne podejście to świadome podejście
Z danymi często jest tak, że nie ma jednej drogi jak uzyskać dany cel, zazwyczaj można podejść do problemu na sto różnych sposób. Jakie jest poprawne podejście? W większości przypadków nie uzyskamy na to pytanie jasnej instrukcji jak postępować krok po kroku, ale jedno jest pewne: świadomość jest kluczowa.
Cokolwiek nie robimy z danymi, warto zastanowić się dlaczego to robimy. Jaka są plusy i minusy tego rozwiązania, jaka jest alternatywa. Podejście automatyczne, podejście „bo gdzieś tak usłyszałam” to podejście bylejakie, i chociaż czasem zadziała, to nie jest to sposób w jaki powinno się pracować z danymi. Jeżeli podjąłeś się jakiejkolwiek transformacji danych bez zastanowienia, to może to być niewłaściwe podejście, jeśli jednak zastanowiłeś się dlaczego postępujesz w ten sposób i świadomie zdecydowałeś się na kontynuację tej drogi, to poprawnie podchodzisz do danych.
Podsumowanie (take-home messages)
- Nie ma ogólnej analizy danych, nie ma analizy danych bez celu.
- Analiza danych w dużej mierze polega na porównywaniu wartości między sobą. Porównuj różnice w grupach lub zmiany w czasie.
- Dokonując operacji na danych miej cały czas z tyłu głowy poziom agregacji.
- Pamiętaj, że wybór miary ma znaczenie. Zazwyczaj mediana jest lepsza niż średnia, a poznanie całego rozkładu jest lepsze od pojedynczych wartości.
- Używaj wizualizacji do interpretacji danych.
- Sprzątanie danych to nie fanaberia, a niezbędny krok do uzyskania wiarygodnych wyników.
- Uważaj na nadinterpretacje. Korzystaj z testów statystycznych i testów A/B, aby uniknąć zbyt pochopnych wniosków.
- Często możliwych rozwiązań jest mnóstwo i nie ma jednej drogi na osiągnięcie celu, jednak właściwą drogą będzie świadoma praca na danych.
Uważasz, że artykuł jest przydatny? Będę wdzięczna jak puścisz go w świat i podzielisz się z innymi.
Pamiętaj też o zapisaniu się do newslettera, aby nie ominęły cię nowe treści.
tagi: agregacja, agregacja danych, analityk danych, analiza danych, analizowanie danych, big data, dane, data analysis, data science, interpretacja danych, jak analizować dane, jak zostać analitykiem danych, kiedy używać mediany, mediana, mediana czy średnia, rozkład, rozkład normalny, rozkład prawoskośny, rozkłady danych, sprzątanie danych, statystyka, testy A/B, testy AB, testy statystyczne, wizualizacja danych
Tak bardzo chciałabym, żeby na moich studiach, na statystyce, ktoś zrobił nam taki wstęp. Tymczasem od razu rzucono nas na głęboka wodę i bez wytłumaczenia podstaw przeprowadzaliśmy teoretyczne testy na abstrakcyjnych zbiorach danych.
Odnośnie agregacji- dobrze myślę, że jednym z takich typowych błędów poziomu jest wniosek, że skoro ludzie mają 2 nogi, a psy 4, to średnio mamy 3 nogi?
Moim zdaniem największym błędem w tym słynnym przypadku jest sprowadzenie statystyki do jednej wartości, czyli do średniej. Gdybyśmy wiedzieli jak wygląda rozkład nóg wszystkich przypadków, czyli, że albo mamy 4 nogi albo 2 to zdalibyśmy sobie sprawę, że mamy do czynienia z dwoma grupami przypadków i bez sensu jest wyciąganie z nich średniej.