Za każdym razem gdy wspominam o programie do wizualizacji (typu Tableau, Power BI czy Looker) to dostaje pytanie w stylu:
“A w sumie po co komu ten program do wizualizacji? Czemu nie zrobić wykresów w pythonie?”
No bo w sumie po co komu specjalny program, który trzeba zainstalować, skonfigurować, podłączyć pod źródło danych i jeszcze za niego zapłacić, skoro można to samo zrobić w pythonie za darmo? W tym poście znajdziecie odpowiedź na to pytanie.
W tym artykule dowiedziecie się:
- czy python jest zawsze najlepszym rozwiązaniem
- czego nie uczą kursy online
- czym się różni statyczna i dynamiczna analiza danych
- jaka jest przewaga programów do wizualizacji
- kiedy warto używać pythona
- co zrobić, kiedy python jest wymagany
Python jako ostatni krok w ewolucji obsługi danych?
Zacznę od mojej obserwacji: mam wrażenie, że niektórym się wydaje, że python jest zawsze najlepszym rozwiązaniem. Że jest lepszy od excela, lepszy od SQL, lepszy od programów do wizualizacji. Że skoro python jest trudniejszy do nauki czy też bardziej zaawansowany to praca w pythonie jest zawsze bardziej profesjonalna i jeżeli używamy czegokolwiek innego to: a) nie znamy się, b) nie potrafimy programować, albo c) robimy to gorzej, bo można to lepiej zrobić w pythonie.
Czy tak jest rzeczywiście? Nie. Co jest najbardziej profesjonalne? Używanie adekwatnego narzędzia do problemu. Co jest adekwatnym narzędziem do danego problemu? Najprostsze właściwe rozwiązanie.
Przykład? Jeżeli dane są składowane w relacyjnej bazy danych (jak to zazwyczaj ma miejsce) to powinniśmy użyć SQL do prostych obliczeń, np. ile mieliśmy transakcji w tym tygodniu:
SELECT COUNT(*)
FROM transactions
WHERE date_trunc('week', created) = date_trunc('week', now())Błędem byłoby ściągnięcie wszystkich transakcji za pomocą SQL do pythona a następnie odfiltrowanie ich i policzenie w tym języku. Python nie wniósłby w tym przypadku żadnej dodatkowej funkcjonalności oprócz zbędnego skomplikowania kodu, a w dodatku pobieranie wszystkich rekordów niepotrzebnie obciążyłoby bazę danych.
Wybranie “trudniejszego” narzędzia zatem nie jest lepsze, nie jest też bardziej profesjonalne. Wybranie zbyt skomplikowanego narzędzia do rozwiązania problemu jest po prostu błędem. Najbardziej profesjonalne jest użycie właściwego narzędzia, czyli takiego, które rozwiąże je w sposób prawidłowy i powtarzalny, ale jak najmniejszym kosztem.
Kursy online nie uczą rzeczywistej pracy na danych
Kursy online do nauki analizy danych nie do końca są w stanie zobrazować jak wygląda rzeczywista praca w firmach. Według mnie:
- Kursy niedostatecznie podkreślają, że odbiorcami analizy zazwyczaj nie są sami analitycy danych ale ludzie nietechniczni, np. z działu biznesowego lub produktowego. Analityk danych często tworzy analizy aby inni ludzie mogli podejmować decyzje na ich podstawie, zatem musi je stworzyć w sposób dostępny dla innych.
- Kursy kiepsko obrazują, że dane zmieniają się w sposób ciągły.
Ciągłe monitorowanie vs stateczna analiza
Robiąc kurs często dostajemy zestaw danych i mamy coś z nim zrobić: analizę, wizualizacje, model uczenia maszynowego czy cokolwiek innego. Ucząc się w taki sposób wyobrażamy sobie, że tak właśnie wygląda ta praca: dostajemy jakieś dane, robimy co mamy zrobić i zamykamy dany projekt.
W rzeczywistości jednak dane spływają cały czas i bardzo często musimy tworzyć analizy dynamiczne, czyli analizy zmieniające się wraz ze zmianą danych. Analizy powinny się aktualizować bez udziału analityka, aby osoby nietechniczne miały zawsze dostęp do najświeższych danych.
Aby zobrazować to na przykładzie:
- Analiza statyczna miałaby miejsce, gdy ludzie biznesowi zapytali nas o podsumowanie sprzedaży w sklepie internetowym w lipcu. Czekamy aż lipiec się skończy aby móc ściągnąć wszystkie dane z tego miesiąca. Ściągamy je, analizujemy i wysyłamy raport do osób zainteresowanych wynikami.
- Analiza dynamiczna ma miejsce gdy na bieżąco pokazuje co się wydarzyło w ciągu ostatnich X dni. Nie musimy czekać do końca lipca aby przygotować z tego miesiąca raport, ponieważ pokazujemy jak sytuacja się zmienia cały czas – np. już 2 lipca możemy zobaczyć jak wyglądała sprzedaż 1 lipca. Naturalnie po zakończeniu miesiąca można spojrzeć na cały poprzedni miesiąc.
Ciężko zaprzeczyć temu, że druga opcja jest lepsza – nie dość, że zapewnia wszystko to co pierwsza (możemy podsumować cały miesiąc po jego zakończeniu), to jeszcze możemy w sposób ciągły monitorować sytuację i na bieżąco na nią reagować.
Ja sama duuuużo częściej w pracy spotykam się z drugim przypadkiem i uważam, że świat biznesu idzie w tym kierunku – analiza danych służy reagowaniu na informacje z danych, a nie na raportowaniu czy podsumowywaniu przeszłości.
“Problem” polega tylko na aspekcie technicznym – musimy mieć narzędzia umożliwiające tworzenie analiz, które będą się same odświeżać.
I tutaj wjeżdża na białym koniu program do wizualizacji
Funkcją programów do wizualizacji jest właśnie umożliwienie ciągłego i automatycznego monitorowania danych przez osoby nietechniczne. To jest coś do czego te programy zostały stworzone. Jest to możliwe ponieważ:
- Mają bezpośredni dostęp do źródła danych, np. relacyjnej bazy danych. Za każdym razem gdy otwieramy wizualizacje to tworzą się one od nowa, zatem zawsze obrazują najświeższe dane.
- Działają dynamicznie – mają filtry, które umożliwiają wybór poszczególnych dni, typów danych itd. Odbiorca analizy może sam przestudiować rzeczy, które go interesują, nie musi prosić o pomoc analityka danych.
- Umożliwiają łatwy dostęp do wykresów osobom nietechnicznym – zazwyczaj dostępne są w postaci linka w przeglądarce internetowej, przez nie trzeba nic instalować.
Jak wygląda typowy flow pracy na zmieniających się danych:
W programie do wizualizacji analityk danych buduje dashboard, czyli zbiór wykresów na dany temat. Analityk jest odpowiedzialny za wyciągnięcie, przetworzenie i przygotowanie danych oraz stworzenie wykresów. Gotowy dashboard jest udostępniany za pomocą linka w przeglądarce, aby ludzie z działu biznesowego mogli na bieżąco monitorować sytuację. Mogą sobie na niego wchodzić codziennie, raz w tygodniu czy w miesiącu i za każdym razem wybierać okres czasu jaki ich interesuje. Analityk nie musi odświeżać dashboardu lub zmieniać filtrów – wszystko działa na zasadzie klikania myszką zatem osoby nietechniczne radzą sobie same.
Dlaczego python jest gorszy do ciągłego monitorowania?
Z racji tego, że python jest językiem programowania to umożliwia dużą elastyczność, ale… no właśnie, to jest tylko język programowania.
Osoby myślące o pythonie jako narzędziu do wizualizacji prawdopodobnie myślą o statycznej analizie – mamy jakiś zestaw danych, instalujemy pythona na naszym komputerze, wrzucamy do niego dane, tworzymy wykresy i problem rozwiązany.
Co w przypadku potrzeby ciągłego monitorowania?
Pierwszy problemem jest jak podzielimy się wykresami stworzonymi w pythonie z odbiorcami nietechnicznymi. Wykres stworzony w pythonie jest dostępny w danym środowisku pythonowym, nie jest on publiczny czy dostępny dla reszty. Moglibyśmy zapisać go w HTMLu a następnie wysłać mailem do odbiorców, ale stworzymy wtedy statyczny raport bez możliwości zmiany.
Niby istnieją frameworki pythona do budowania dynamicznych dashboardów z filtrami (np. dash), ale wciąż budują one dashboard na lokalnej maszynie – nie są one z założenia dostępne dla innych odbiorców i nie odświeżają się automatycznie. Możemy je zautomatyzować, ale… tutaj pojawiają się schody. Musimy mieć miejsce, w którym python się będzie odpalał, np. chmurę. Musimy kontrolować wersję pythona, np. poprzez kontyneryzację. Musimy zintegrować ze sobą różne systemy, np. połączyć pythona z bazą danych, w których składowane są dane.
Ogarnięcie tego wszystkiego wymaga dość zaawansowanej wiedzy z zakresu devopsu. Wychodzi na to, że aby zautomatyzować tworzenie publicznych dashboardów w pythonie trzeba… praktycznie zbudować program do wizualizacji od nowa!
Kiedy warto robić wizualizacje w pythonie?
Czy to znaczy że w pracy nie używa się pythona do wizualizacji? Oczywiście, że się używa. Wizualizacje w jupyterze notebooku są bardzo użyteczne gdy mamy do czynienia z jednorazową lub statyczną analizą. Na przykład gdy odbiorcami wizualizacji jesteśmy my sami: gdy musimy podjąć jakieś decyzje na podstawie danych to wrzucamy je do pythona, rysujemy co trzeba, podejmujemy decyzje i już. Albo gdy tworzymy raporty statyczne, które muszą być jednorazowo dostarczone do różnych odbiorców.
Co w sytuacji, gdy musimy monitorować coś, co da się zrobić tylko w pythonie?
Sytuacja gdy SQL i funkcjonalność programów do wizualizacji nie dają rady i trzeba jednak użyć pythona oczywiście ma miejsce dość często (szczególnie w pracy DS). Przykładem jest monitorowanie wyniku modelu uczenia maszynowego. Co zrobić w takiej sytuacji? Standardem biznesowym jest:
- ściągnięcie danych za pomocą SQL do pythona
- przerobienie danych w pythonie (np. zrobienie ML)
- wrzucenie przetworzonych danych (np. predykcji modelu) do bazy danych
- wizualizacja danych za pomocą programu do wizualizacji
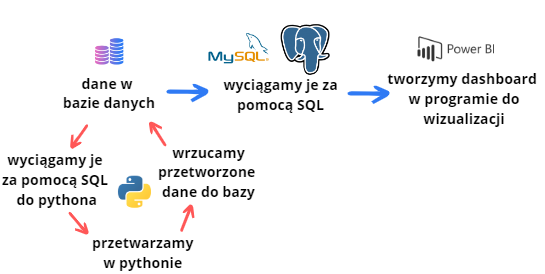
Jak jednak można się domyślić automatyzacja tego wszystkiego i tak wymaga postawienia infrastruktury do pythona (czyli kod pythonowy powinien się automatycznie odpalać w chmurze itd.), jednak tego nie przeskoczymy. Chodzi o to, aby nie tworzyć od nowa infrastruktury do dashboardów. Wrzucamy wszystko do bazy danych, a resztą się zajmuje program do wizualizacji – a my nie musimy odkrywać koła na nowo i zajmować się tym, co te programy robią.
Typowy przebieg pracy gdy potrzebujemy zwizualizować dane:

Gdy potrzebujemy użyć pythona:
Podsumowanie
- Python nie zawsze jest najlepszym wyborem do rozwiązania każdego problemu.
- W pracy DA i DS często monitorujemy dane w sposób ciągły, a nie robimy statycznych analiz.
- Program do wizualizacji to program wyspecjalizowany do tworzenia dashboardów ponieważ umożliwia prosty dostęp do najświeższych danych przez osoby nietechniczne.
- Python jest językiem programowania w którym można tworzyć wykresy. Nie jest wyspecjalizowany do prostego tworzenia dynamicznych i automatycznie się odświeżających dashboardów dla ludzi nietechnicznych.
- Wizualizacje w pythonie tworzymy najczęściej gdy robimy raporty statyczne lub używamy wykresów do podjęcia własnych decyzji.
Super artykuł Kasia! Jako BI Dev z ponad
letnim doświadczeniem w pełni zgadzam się z Twoimi wnioskami . Nieumiejętne wykorzystanie popularnych narzędzi to chleb powszedni w korpo. Tutejsza architektura zazwyczaj jest planowana na kolanie przez osoby z bardzo wąska specjalizacją. Powstają produkty będące totalnym zaprzeczeniem efektywnego wykorzystania rozmaitych narzędzi np. do wizualizacji danych, które w swoim założeniu miały ułatwiać i niejako zautomatyzować proces eksploracji danych (szczególnie dla userow biznesowych). Często o tym zapominamy i próbujemy forsować rozwiązania, które są swoistym przerostem formy nad treścią. Power point przyjmie wszystko :))
Python jest dobry do ML i DS. SQL do odpytywania dużej ilości danych. Tableau/Power Bi to najprostszy (ale nie najtańszy!) sposób na stworzenie interaktywnych dashboardow. Excela zostawcie finansistom liczącym słupki z budżetami 😉
Również podpisuję się pod wnioskami z artykułu. Uważam, że warto poruszyć również aspekt tego jak firmy korzystają z tych raportów. Oczywiście to „inna para kaloszy”, ale za tym stoi masa pracy analityków, koszty utrzymania infrastruktury etc. Z mojego doświadczenia – mamy dashboardy, które są wykonane w googlowym Datastudio, a pod spodem stoją na tabelach w bigquery na GCP (wszystko jest zautomatyzowane przy pomocy procedur, schedulerów, oparte na zdarzeniach etc.) i co z tego? Dashboardy odwiedza bardzo mała grupa osób (udostępniane są średnio grupie kilkudziesięcioosobowej lub czasem większej) – monitorujemy ich wykorzystanie. Niestety po udostępnieniu takiego raportu bardzo rzadko ktoś do niego wraca. Zapotrzebowanie na nowe raporty jest, tylko co z tego, gdy już powstaną to nikt z nich nie korzysta? Odbiorcy uczestniczą przy procesie tworzenia, omówione są wymagania i potrzeby, więc odpada rozmijanie się z oczekiwaniami biznesu.
Za to takie zestawienia w excelu? Owszem, bardzo chętnie! Mam wrażenie, że bolączką wielu korporacji jest ograniczenie do excela, a czasem (o zgrozo!) nawet do PDF.