Ogłoszenia parafialne
- Post przedstawia dlaczego i jak używać gita i githuba.
- Jest skierowany dla osób, które na co dzień nie pracują na githubie – dla osób, które nie rozumieją co tzn. commit, branch, pull request.
- Post tłumaczy krok po kroku wszystkie podstawowe funkcjonalności korzystając z repozytorium crappydata. Zalecane jest abyście sami próbowali przeklikać się przez to co jest opisywane (uwaga! niestety repo się zmieniło w trakcie, także widok w repo jest inny niż na zdjęciach), albo założyli własne konto na githubie i utworzyli repozytorium, które pozwoli wam na pełne zmiany (na moim repo nie będziecie mogli dokonywać zmian).
- Na końcu jest zadanie domowe.
- Subskrybenci z newslettera dostali dodatkowo quiz, który sprawdza ich praktyczną wiedzę. Aby go rozwiązać będą musieli poszperać w moim repozytorium rzeczy, które zazwyczaj szuka się w repozytoriach w pracy. Zapisy do newslettera na dole strony.
Co powinniście powiedzieć po przeczytaniu artykułu i zrobieniu zadania domowego jak rekruter spyta was o wiedzę na temat githuba? Rozumiecie zasadę działania gita oraz githuba. Potraficie używać githuba za pomocą interfesju graficznego na stronie. Nie potraficie jeszcze używać githuba z lokalnego komputera i terminala, ale nauka tego nie powinna sprawić wam większych problemów, ponieważ rozumiecie już główne koncepcje githuba.
Jeszcze jedno ogłoszenie parafialne: jeżeli myślisz „nie korzystamy w pracy z githuba, nic tu po mnie” to pozwól mi wytłumaczyć ci w 3 punktach, dlaczego jednak warto:
- Jest więcej niż prawdopodobne, że twoja firma używa już githuba (lub tożsamą platformę) – po prostu używają go programiści, a nie analitycy danych lub data scientiści. W takiej sytuacji trzeba „tylko” przekonać osobę decyzyjną, że dla ludzi siedzących w danych github jest równie ważny jak dla programistów.
- Github nie jest zmianą, która jakkolwiek wpłynie na resztę narzędzi w twojej firmie. Zresztą większość rzeczy o których piszę to nie są duże zmiany – nie namawiam nikogo na ogromne zmiany w stylu: „zmień narzędzie do wizualizacji wpływające na dziesiątki pracowników„. Używanie kontroli wersji to zmiana wymagająca małego wysiłku, a niesamowicie poprawiająca jakość pracy. Diabeł tkwi w szczegółach – startupy technologiczne nie używają całkowicie innych narzędzi w całkowicie inny sposób, po prostu wykorzystują dużo dobrych praktyk co z czasem stwarza efekt kuli śnieżnej kumulując się w niezwykle efektywną i skuteczną analizę.
- Jak będziecie szukać nowego stanowiska, to powinniście zwracać uwagę na to, czy wasz przyszły pracodawca stosuje dobre praktyki. Im lepsze technicznie firmy znające się na dobrych praktykach tym więcej korzyści dla was – więcej się nauczycie, będziecie robić ciekawsze projekty, pracować z bardziej ogarniętymi ludźmi, więcej zarabiać i to wszystko doprowadzi was do większej satysfakcji z pracy. Serio!
Co to jest git oraz github?
Git to kontrola wersji, która umożliwia składowanie kodu oraz śledzenie jego zmian. Github (oraz inne strony typu bitbucket, gitlab itd.) to platforma do hostowania i zarządzania repozytoriami gitowymi.
Dlaczego git to must have?
Zastanówmy się – co jest alternatywą? Zapisywanie kodów w plikach i trzymanie ich w zwykłych folderach na naszych komputerach albo wspólnym dysku. Takie przetrzymywanie kodu jest beznadziejnym rozwiązaniem ponieważ powoduje masę problemów:
- Jak usuniemy przez przypadek plik, zapomnimy go zapisać albo zapomnimy, gdzie go zapisaliśmy – nasza praca jest kompletnie stracona.
- Jak coś zmienimy w pliku i go nadpiszemy, to nie będziemy w stanie wrócić do poprzedniej wersji.
- Nie jesteśmy w stanie pracować z innymi osobami na tym samym kodzie w tym samym czasie. Nie jesteśmy w stanie szybko dzielić się kodem i zapewnić, że druga osoba pracuje na jego najnowszej wersji.
- Jak mamy 2 pliki i chcemy porównać czym one się różnią, to musimy to robić ręcznie linijka po linijce (jest to w ogóle możliwe?).
Wszystkie te powyższe problemy magicznie znikają gdy zaczynamy używać kontroli wersji.
Git umożliwia:
- składowanie kodu
- łatwe dzielenie się kodem z innymi ludźmi, zarówno technicznymi jak i biznesu
- łatwą kolaborację – różne osoby mogą pracować na tym samym kodzie/projekcie w tym samym czasie nie przeszkadzając sobie wzajemnie
- posiadamy historię kodu! łatwo możemy śledzić zmiany w kodzie z dokładną datą zmian
- możliwość powrotu do poprzedniej wersji kodu
- możliwość automatyzacji w przypadku gdy git jest zintegrowany z innymi narzędziami
- możliwość łatwego sprawdzania poprawności kodu przez współpracowników
Krok po kroku
Przejdziemy teraz krok po kroku przez najważniejsze funkcje dostępne na githubie. Zachęcam do robienia ich we własnym zakresie – póki co możecie próbować przeklikać się przez moje repo razem ze mną, a w ramach pracy domowej (na dole strony) założyć własne repozytorium, które umożliwi wam robienie w nim zmian (w moim repo niestety zmian nie wprowadzicie).
Repozytorium
Wchodząc na stronę https://github.com/kdyl/crappydata wchodzicie do mojego repozytorium (w skrócie repo). Jest to przestrzeń w której możemy składować foldery oraz pliki. Coś jak dysk googla – tam też możemy tworzyć foldery oraz pliki – ale wyspecjalizowane w przechowywaniu kodu.
Na górze zobaczycie nazwę użytkownika (kdyl) oraz nazwę repo (crappydata). Z defaultu otwiera nam się zakładka z kodem (Code) oraz główny branch (main), w którym są 2 pliki – plik README.md oraz cte.sql. Plik README jest plikiem tekstowym, który służy do opisu, instrukcji. Jego zawartość jest od razu wyświelona na stronie, nie musimy w niego klikać (ale możecie, aby potwierdzić, że jest to ta sama treść) – u mnie jest to tylko link do bloga.
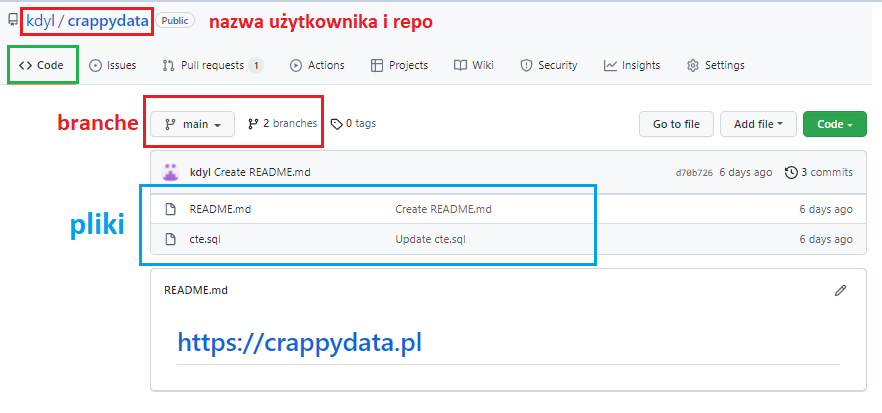
Pliki
Kliknijmy sobie w nazwę pliku cte.sql. Otwiera nam się kod w rozszerzeniu .sql. Oprócz kodu widzimy użyteczne informacje – autora ostatniej zmiany, liczbę osób pracujących na pliku. Z tego miejsca możemy zmienić plik lub go usunąć. Możemy też wejść w historię kodu.
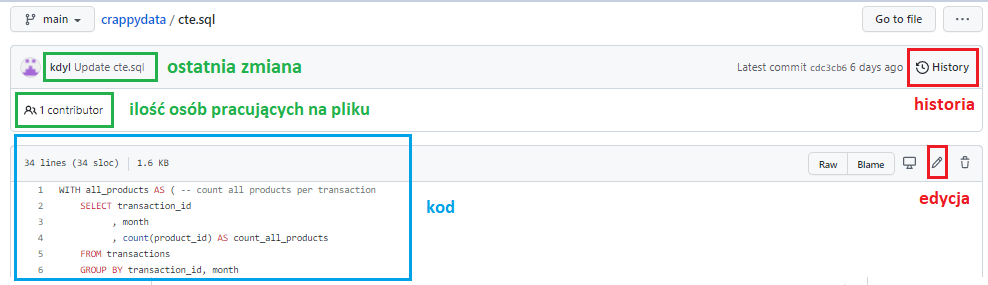
Historia i commity
Kliknijmy w history w prawym górnym rogu. Tutaj zaczyna dziać się magia. Widzimy 2 rekordy – 2 tzw. commity czyli zmiany wprowadzone w pliku.
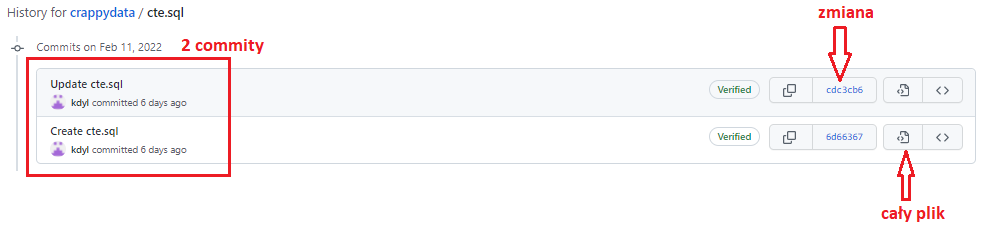
Możemy zobaczyć szczegóły zmiany albo klikając w tekst commita Create cte.sql albo w kod commita (zaznaczony na screenie jako zmiana) po prawej stronie.
Klikając w commit Create cte.sql widzimy cały plik na zielono, co znaczy że w tym commicie cały kod został dodany do repozytorium. Klikając za to w Update cte.sql widzimy już zmiany, które zostały dokonane na kodzie:
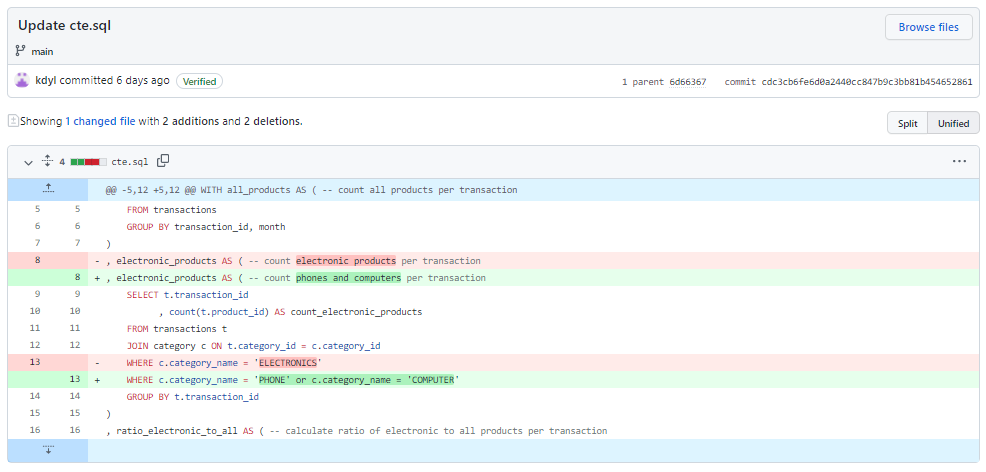
Na czerwono widzimy usunięty a na zielono dodany kod. Dodatkowo podkreślone są poszczególne słowa które zostały zmienione w linijce. W linijce 8 został zmieniony komentarz z count electronic products per transaction na count phones and computers per transaction a w linijce 13 warunek z WHERE c.category_name = 'ELECTRONICS' na WHERE c.category_name = 'PHONE' or c.category_name = 'COMPUTER'
Branche
Kolejną magiczną cechą związaną z gitem są branche. Dotychczas nawigowaliśmy między różnymi stronami będąc cały czas na branchu głównym (main), który stanowi główny, zaakceptowany kod.
Tworząc branch duplikujemy repozytorium i tworzymy coś w stylu alternatywnej rzeczywistości. Na branchach możemy robić co nam się żywnie podoba – usuwać, dodawać, zmieniać pliki i nie ma to absolutnie żadnego wpływu na to co się dzieje na głównym kodzie na branchu main. Zresztą zobaczmy jak to wygląda w praktyce – cofnijmy się do głównej strony repo i zobaczmy jakie mamy branche klikając w main:
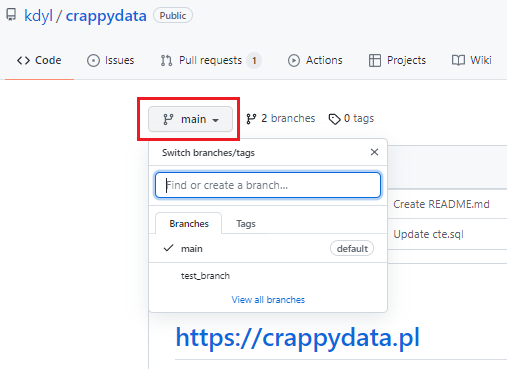
Pokazuje nam się branch main wraz z ptaszkiem potwierdzającym, że obecnie się na nim znajdujemy, oraz kolejny branch, nazwany test_branch -> kliknijmy sobie w niego:
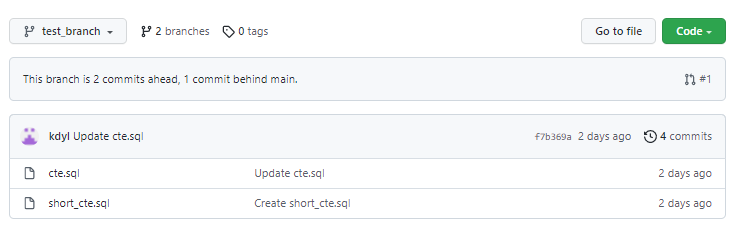
Co tutaj widzimy? Inne pliki! Zniknął plik README.md oraz pojawił się plik short_cte.sql. Możemy zacząć eksplorować ten branch – np. jak wejdziecie w plik cte.sql a następnie w history to zobaczycie, że historia tego pliku ma aż 3 rekordy, a nie 2 jak miała na branchu main!
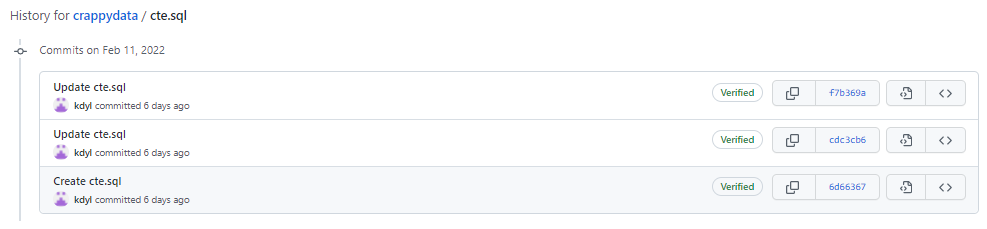
Wchodząc w ostatniego committa zobaczycie, że został dodany kolejny warunek do kodu. Tak jak pisałam – każdy branch to alternatywna rzeczywistość naszego repozytorium. Zmiany wprowadzane na branchu dotyczą tylko tego brancha.
O co chodzi z tymi branchami? Chodzi o to, aby każdy mógł sobie pracować nad swoimi zmianami nie wchodząc w kolizję z innymi osobami. Zaczynając nowe zadanie tworzymy sobie kopie repozytorium tworząc nowy brancha -> zmieniamy (commitujemy) to co trzeba nie psując innym żadnego kodu -> na sam koniec jak jesteśmy pewni wszystkich zmian możemy je połączyć i zintegrować z głównym branchem main – process ten to tzw. merge.
Merge i pull request
Jak jesteśmy zadowoleni z wszystkich zmian i gotowi do wrzucenia ich do głównego brancha main to otwieramy tzw. pull request (PR) (nazywany w niektórych kontrolach wersji merge request). Pull request służy także do weryfikacji naszego kodu przez wpółpracowników.
Klikamy w zakładkę Pull requests. Widzimy listę otwartych PRów oraz po prawej stronie możemy otworzyć kolejny.
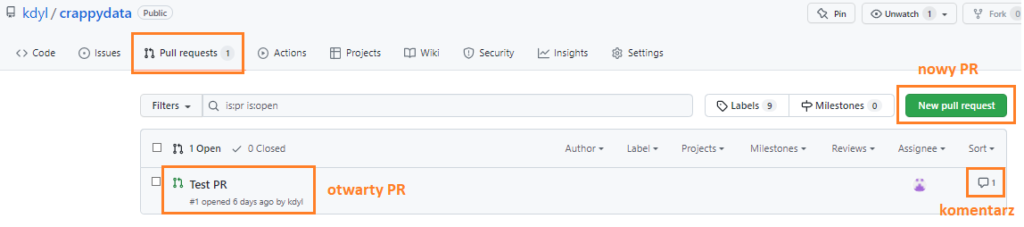
Wejdźmy sobie w Test PR:
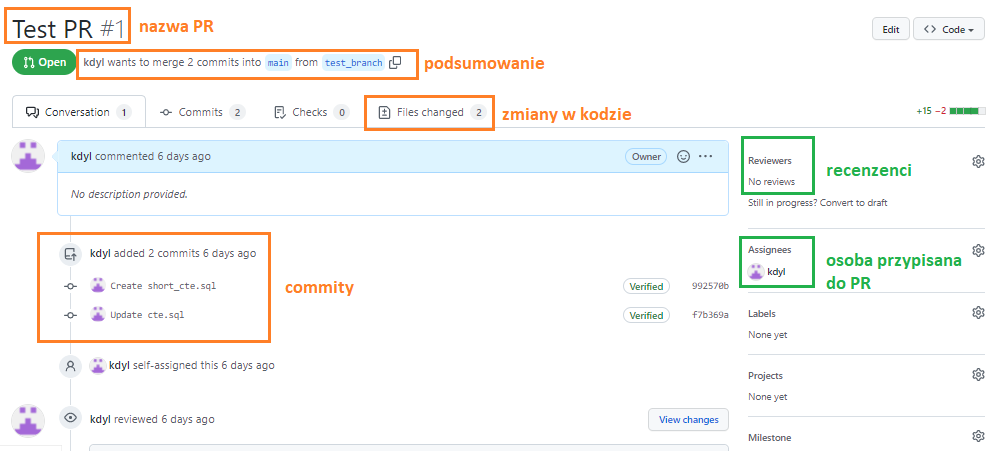
Na górze widzimy nazwę, numer oraz status PRa. Obok tego widzimy praktycznie opis co ten PR ma na celu:
kdyl wants to merge 2 commits into main from test_branch
CZYLI: użytkownik kdyl chce zmergować branch test_branch, który zawiera 2 commity (2 zmiany) do brancha main.Poniżej widzimy commity zrobione na branchu (możemy na nie kliknąć). Po prawej stronie mamy wypisanego assignee, czyli osobę przypisaną do PR (zazwyczaj twórca) oraz reviewers, czyli osoby, które powinny zrecenzować kod (w moim przypadku nie ma nikogo).
Głównym celem pull requestów jest recenzja kodu przez naszych współpracowników. Powinni się oni udać do zakładki Files changed, gdzie widać zmiany w kodzie.
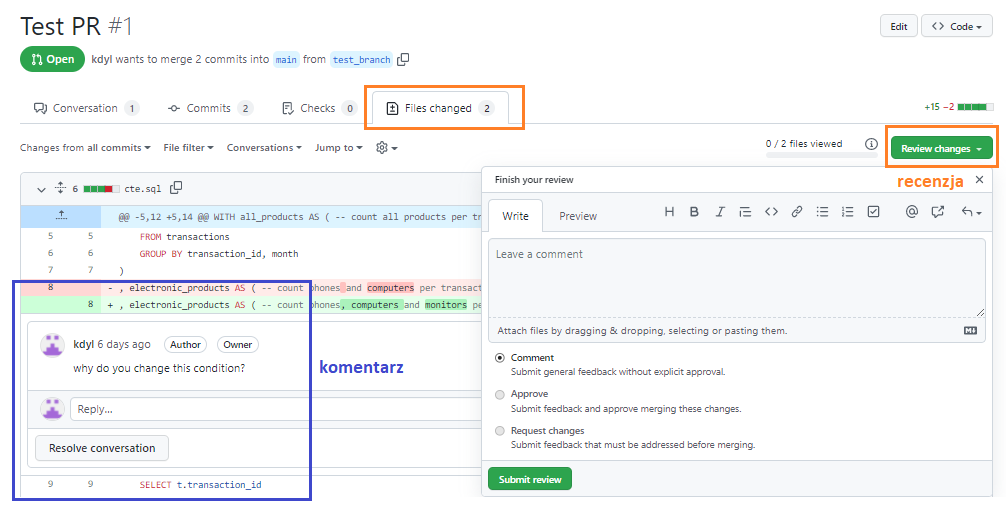
Zielony przycisk po prawej stronie umożliwia rozpoczęcie recenzji – możemy:
comment– dodać komentarzeapprove– potwierdzić, że z kodem wszystko jest ok przez co merge będzie możliwy (w moim przypadku mogę zrobić merge bez approve, ponieważ takie mam ustawienia. Można to zmienić i umożliwić merge tylko w przypadku, gdy ktoś kliknie approve)request changes– wtedy merge zostanie zablokowany dopóki recenzent go nie odblokuje.
Co najlepsze w recenzjach, to to, że można komentować pojedyńcze linijki. Jak najedziemy nad linijkę to pojawia się plusik – możemy wtedy dodać komentarz, który ja dodałam do linijki numer 8.
W zakładce Conversation na dole strony widzimy zielony przycisk Merge pull request – kliknięcie w niego oznaczałoby merge, czyli wszystkie zmiany zrobione na branchu test_branch połączyłyby się z branchem main.
Typowy flow pracy
Uffff, dużo tego! Postarajmy się podsumować krok po kroku typowy flow pracy jak dostajemy nowe zadanie:
1. Wchodzimy na główną stronę repo na branch main
2. Zakładamy nowego brancha – klikamy w main -> wpisujemy nazwę nowego brancha -> create branch…
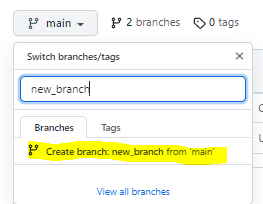
3. Będąc na nowym branchu robimy zmiany – dokonujemy tzw. commitów:
Możemy dodać nowy plik z głównej strony repo:

Lub zmienić lub usunąć istniejący plik wchodząc w niego i wybierając w prawej górnym rogu:

Zmiany musimy tzw. commitować, czyli kliknąć commit na dole strony.
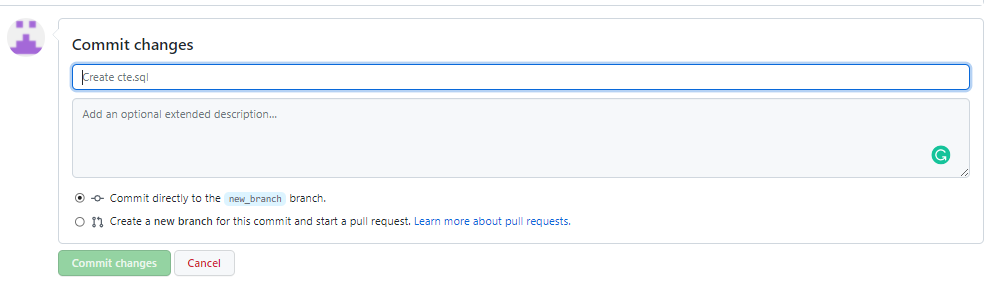
4. Jak jesteśmy zadowoleni z wszystkich zmian i gotowi do wrzucenia ich do głównego brancha main to musimy otworzyć pull request
5. Robimy merge -> zmiany pojawiają się na branchu main!
Wersje repo
Rozumiejąc już podstawy jak działa kontrola wersji, wróćmy na koniec do teorii. Tak jak już wspominałam, każde repozytorium może mieć inne ustawienia i „zasady”. Co jednak najważniejsze, to istnieją 2 typy repozytoriów:
- nie zintegrowane z żadnym środowiskiem -repozytoria służące składowaniu kodu, a nie jego automatyzacji lub uruchamianiu. Wrzucanie kodu do takiego repo nic nie powoduje, nic nie uruchamia. Nawet jeżeli wrzucimy nie działający kod to nic się nie stanie.
- zintegrowane z programami/środowiskami – służą nie tylko składowaniu kodu, ale także jego automatyzacji i uruchamianiu. Mogą np. być połączone z programem do wizualizacji – wtedy jak coś mergujemy to następuje zmiana w tym programie (np. kod liczący KPI się zmienia przez co zmienia się wykres na dashboardzie). W takim przypadku musimy wrzucać tylko działający kod, ponieważ błąd w kodzie może spowodować realne błędy na produkcji.
Rodzaje pracy z githubem
Dzisiaj przeszliśmy sobie przez repo używając graficznego interfejsu na stronie githuba. Nie jest to jedyna możliwość pracy z githubem, aczkolwiek jest najprostsza i najlepsza na zrozumienie podstaw. Z czasem wiele osób przerzuca się do pracy na sklonowanym repo na własnym komputerze.
Sklonowanie repozytorium na własny komputer powoduje, że całe repo tworzy się w formie folderu, zachowując organizację folderów i plików widoczną na stronie:
Możemy wtedy zmieniać branche używając komendy gita w terminalu albo używając specjalnych programów np. Sourcetree. Pracując lokalnie dochodzą nam dodatkowe komendy do komunikacji ze zdalnym repozytorium – pull (zaciąganie zmian) oraz push (wypychanie zmian). Dodatkowa wiedza w tym temacie wychodzi poza ramy dzisiejszego posta.
Zagrożenia
Na koniec warto wspomnieć o zagrożeniach wynikających z pracy z githubem. Co najistotniejsze – git przechowuje całą historię wszystkich commitów – więc cokolwiek scomittowaliście, na zawsze zostaje to w repozytorium. Nawet jak usuniecie branch. Dlatego trzeba uważać, aby nie commitować:
- haseł, tokenów – nigdy nie hardcodujemy haseł w kodzie!
- informacji poufnych – jak robicie analizę w jupyterze notebooku, to powinniście przed wrzucaniem go na repo usunąć wszystkie outputy! (chyba, że chcecie się pochwalić wynikami na własnym prywatnym githubie, ale w pracy nie powinniście tego robić)
- dużych plików – jak wrzucicie duży plik CSV to już na zawsze repo będzie przechowywać duży niepotrzebny plik! Wtedy klonowanie go na komputer powoduje niepotrzebne kopiowanie tych dużych nieużytecznych plików. Repozytoria służą przechowywaniu kodu, a nie przechowywaniu danych, więc wrzucanie danych jest złą praktyką.
Podsumowanie
Omówiliśmy sobie:
- co to jest kontrola wersji i dlaczego warto ją używać
- jakie są typowe pojęcia (repo, branch, commit, pull request, merge) związane z gitem
- jak wygląda typowy flow pracy z githubem
- jakie są rodzaje repo i jak możemy na nim pracować
- zagrożenia
Jakie kolejne artykuły przewiduje w tym temacie:
- praca na repo z własnego komputera
- dobre praktyki – to, że niektórzy korzystają z githuba w pracy to nie znaczy od razu, że potrafią z niego dobrze korzystać. Trafiając do jednej firmy byłam w szoku, jak można zbeszcześcić to piękne narzędzie.
Praca domowa
Nie utrwalimy wiedzy dopóki sami nie spróbujemy zacząć robić – dlatego zachęcam do odrobienia pracy domowej oraz przejścia quizu (dostępny tylko dla subskrybentów newslettera).
- Załóż konto na githubie i utwórz swoje repozytorium
- Utwórz swój pierwszy plik (patrz na screen poniżej)
- Utwórz nowy branch o nazwie
my_new_branch - Dodaj na branchu
my_new_branch2 różne pliki z kodami SQL (albo zwykłym tekstem) - Zmień kod w jednym z plików
- Usuń drugi plik
- Utwórz
pull request - Sam(a) sobie zrób recenzję kodu! Dodaj komentarz do kodu w pull requeście a następnie kliknij approve.
- Kliknij merge pull request i zobacz co się stanie na branchu
main

Newsletter
Aby zostać info o nowych postach zapraszam do subksrypcji newslettera. Jego subskrybenci dostają ekstra materiały do każdego tematu – tym razem dostali quiz, który sprawdza ich praktyczną wiedzę z githuba. Aby go rozwiązać muszą sami odnaleźć odpowiedzi na pytania w moim repo.
Świetny artykuł, zdecydowanie Twój język przemawia do mnie, Kasiu więcej 👍
Dziękuję bardzo!! ☺️
Pewnie niekoniecznie najlepsze miejsce, ale napiszę tutaj. Ta strona i blog są wspaniałe. Piszesz tak świetnym i zrozumiałym językiem, że to aż dziwne, że jesteś z IT 😉 żałuję, że nie trafiłam na Twojego bloga wcześniej. Są tu tylko potrzebne i wartościowe informacje, a w zalewie tych miernych to, co piszesz się bardzo pozytywnie wyróżnia. Ja zaczynam niedługo swoją pierwszą pracę jako junior w IT, na razie nie dane, ale ciągnie mnie w tę stronę. Na pewno będę czytać wszystko co publikujesz 🙂
Dziękuję za komentarz, naprawdę PRZEMIŁO czytać takie opinie 🙂 Tworzę dla ludzi, więc czytanie takich rzeczy to największa nagroda jaka mnie spotyka. Co do języka IT – sama tak mam do dzisiaj, że dalej nie rozumiem większość osób z IT, więc chyba dlatego zaczęłam prowadzić bloga, żeby przetłumaczyć o co im chodzi 😉
Odnośnik zwrotny: Jak się nauczyć SQL? – Crappy Data